
Standardowy data warehouse czy synapse dedicated pool?
Wybór pomiędzy MS SQL & Synapse Dedicated Pool zależy od konkretnych potrzeb organizacji i rodzaju przetwarzania danych, które mają być obsługiwane.
MS SQL Server to tradycyjna baza danych typu relacyjnego o architekturze monolitycznej, która działa na pojedynczym serwerze lub klastrze serwerów.
Platforma Synapse Dedicated SQL Pool to zaawansowane rozwiązanie bazodanowe typu MPP o architekturze rozproszonej, które umożliwia równoczesne przetwarzanie na wielu węzłach.
Czym jest modern data warehouse?
Nowoczesna hurtownia danych to zaawansowane podejście do zarządzania danymi i analizy, które integruje dane z różnych źródeł i umożliwia efektywną analizę oraz raportowanie. Główne cechy nowoczesnej hurtowni danych:
- Integracja danych z różnych źródeł
- Przechowywanie danych w hurtowni danych
- Rozproszone przetwarzanie danych:
- Elaboracja danych (ETL/ELT)
- Wsparcie dla danych nierelacyjnych
- Analiza danych w czasie rzeczywistym
- Wsparcie dla analizy zaawansowanej i uczenia maszynowego
- Dostęp do danych za pośrednictwem interfejsów self-service
- Elastyczność i skalowalność
- Bezpieczeństwo i zgodność
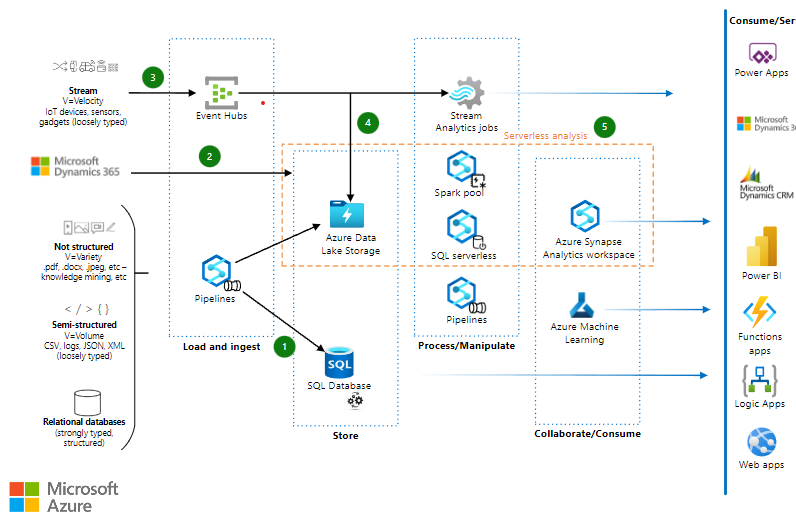
Modern data warehouse to zaawansowana platforma, która integruje i zarządza danymi z różnych źródeł, takimi jak bazy danych, chmurowe usługi lub aplikacje, w sposób efektywny i skalowalny. To umożliwia organizacjom gromadzenie, przetwarzanie i analizowanie dużych ilości danych w czasie rzeczywistym lub w trybie wsadowym.
Platforma Azure oferuje narzędzia do analizy danych, takie jak Azure Synapse Analytics, który łączy w sobie rozwiązania oparte na SQL takich jak dedicated pool oraz możliwość korzystania z rozwiązań serverless z użyciem notebooków w technologii Spark. Ponadto, Azure zapewnia skalowalność i elastyczność, co oznacza, że firmy mogą dostosowywać swoje zasoby do zmieniających się potrzeb i rozmiarów danych. To rozwiązanie pomaga organizacjom usprawnić zarządzanie danymi, zwiększyć efektywność i konkurencyjność na rynku.
MS SQL vs Synapse
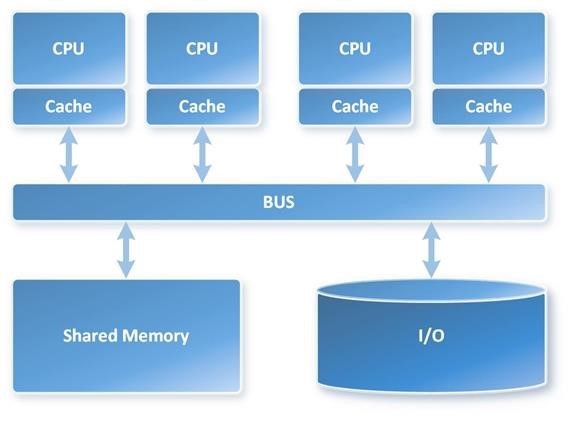
SQL Engine to komponent w bazach danych relacyjnych, który obsługuje zapytania SQL nad danymi w bazie danych.W standardowym SQL Serverze pracujemy z środowiskiem SMP (symteric multi-processing). SMP oznacza, ze mamy pojedynczy storage, który jest połączony z CPUs, a zapytania są równolegle dla tych CPUs po przez service bus. Wszystkie CPUs potrzebuje dostępu do tego samego storage przez co pojawią się wąskie gardło, szczególnie gdy wywołujemy duże zapytania
.MPP to architektura przetwarzania danych, która umożliwia równoczesne przetwarzanie dużych ilości danych na wielu węzłach obliczeniowych. MPP jest szczególnie przydatne w kontekście analizy danych i hurtowni danych.W MPP każdy storage jest szeroko dystrybułowany i zapewnia pewną określoną liczbe obliczeń. Każdy node (węzeł) jest tak naprawdę oddzielna baza SQL i posiada swój własny storage, oddzielony od innych nodów
W SMP może istnieć rywalizacja o zasoby pamięciowe z powodu jednego punktu dostępu, ten problem jest rozwiązany w MPP gdyż każdy node ma własny storage.
Symetric multi-procesising
Massively Parallel Processing Engine

Kluczową sprawą jaką musimy zrozumieć pracując z Azure Synapse Analytics jest dystrybucja.
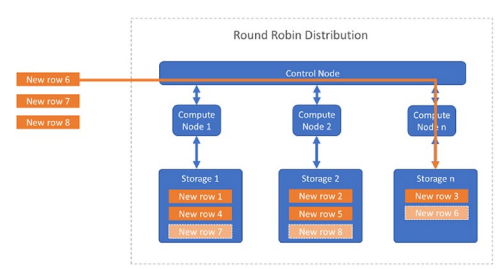
Round robin distribution:
| CREATE TABLE myTable ( id int NOT NULL, firstName varchar(20), lastName varchar(20) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ); |
Hash distribution
| CREATE TABLE myTable ( id int NOT NULL, firstName varchar(20), lastName varchar(20) ) WITH ( DISTRIBUTION = HASH (id), CLUSTERED COLUMNSTORE INDEX ); |

Kluczową sprawą jaką musimy zrozumieć pracując z Azure Synapse Analytics jest dystrybucja.
Zagrożenia po stronie Synapse Dedicated Pool:
Primary key i indexy bez unique key
Niestety nie jesteśmy wstanie zdefiniować unikalnego primary key i/lub utworzyć unikalny index czy constrein. Mimo, że Synapse pozwoli nam utworzyć taki klucz lub index, będziemy musieli wymusić, że nie musi być unikalny
Identity column per node
Niestety funckja identity nie działa tak jakbyśmy tego chcieli. Każdy identity tworzy się na osobnym nodzie, przez co ich numeracja występuje losowo ale unikalnie dla całego control noda.
Data skew
Data skew ma miejsce, gdy dane nie są prawidłowo rozmieszczone w różnych dystrybucjach pamięci masowej.
Szybkim sposobem sprawdzenia Data Skew jest użycie DBCC PDW_SHOWSPACEUSED. Poniższy kod SQL zwraca liczbę wierszy tabeli przechowywanych w każdym z 60 rozkładów. Aby zapewnić zrównoważoną wydajność, wiersze tabeli rozproszonej powinny być równomiernie rozłożone we wszystkich dystrybucjach.
DBCC PDW_SHOWSPACEUSED(’dbo.FactInternetSales’);
Azure Synapse Concurency Slots
Azure Synapse Concurency Slots to liczba zapytań, które można jednocześnie wykonać w bazie danych.
Liczba miejsc współbieżności zależy od liczby zasobów przydzielonych do dedykowanej puli SQL usługi Azure Synapse Analytics.
Na początek w usłudze Azure Synapse Analytics liczba współbieżnych miejsc zależy od jednostek magazynu danych (DWU) przydzielonych do dedykowanej puli SQL.
Jeśli w bazie danych działa jednocześnie wiele zapytań i jest dostępna wystarczająca liczba miejsc współbieżności, niektóre zapytania zostaną umieszczone w kolejce.

Typy danych
Oba systemy wspierają tylko tabularyczny zapis danych
W Synapse nie ma możliwości użycia non/semi-structured data
Dla danych w formacie JSON preferuje się zapis w formacie nvarchar(max) i wykorzystanie funkcji OPENJSON
W Synapse nie powinno używać się typu danych n/varchar(max), zamiast tego lepiej stosować nvarchar(4000). Jeżeli już musimy użyc varchar czy nvarchar(max) możemy ustawić dystrybucje na heap.
Extrenal tables
W takim razie co z danymi non/semi-structured data? Na te zapotrzebowanei przychodzi nam wirtualizacja danych za pomocą external tables.
Tabela zewnętrzna wskazuje dane znajdujące się w usłudze Hadoop, obiekcie blob usługi Azure Storage lub usłudze Azure Data Lake Storage.
Tabele zewnętrzne umożliwiają odczytywanie danych z plików lub zapisywanie danych w plikach w usłudze Azure Storage.
Tabele zewnętrzne możesz wykorzystać do:
Generowania zapytań do usługi Azure Blob Storage i Azure Data Lake Gen2 za pomocą T-SQL.
Przechowuj wyniki zapytań w plikach w usłudze Azure Blob Storage lub Azure Data Lake Storage przy użyciu technologii CETAS.
Importuj dane z Azure Blob Storage i Azure Data Lake Storage i przechowuj je w dedykowanej puli SQL
Tabele zewnętrzne w pulach SQL Synapse można tworzyć, wykonując następujące kroki:
CREATE EXTERNAL DATA SOURCE, aby odwoływać się do zewnętrznego magazynu Azure i określ poświadczenia, których należy używać w celu uzyskania dostępu do magazynu.
CREATE EXTERNAL FILE FORMAT, aby opisać format plików CSV lub Parquet.
CREATE EXTERNAL TABLE na plikach umieszczonych w źródle danych o tym samym formacie pliku.
Porównanie MS SQL vs Synapse Dedicated Pool
