
In this blog, I would like to delve into the possibilities offered by the new Azure AI Studio tool from Microsoft in terms of comparing the capabilities of LLM models. What exactly is Azure AI Studio? Well, quoting the documentation, it is a platform that enables building, testing, and deploying artificial intelligence solutions on the Azure platform. Azure AI Studio brings together capabilities from across multiple Azure AI services in one place. The number of such services created by Microsoft is very large, as is known, and additionally, they are dispersed within various web applications.
To illustrate this:

As you can see, the tool is very extensive, and in this post, I would like to focus only on the 'Benchmark’ functionality, which serves to compare the capabilities of various language models. This feature is particularly useful for developers and data scientists, as it allows for quick and efficient evaluation of different approaches and algorithms in the context of a specific problem. This enables users to choose the most optimal solution for their needs, which is crucial in the process of creating and implementing effective solutions based on machine learning.
Microsoft conducted a comprehensive verification of various versions of GPT (LLM models from OpenAI) and llama (models from Meta). Each model was evaluated based on widely accepted publicly available test datasets. Below is a list of these datasets with a brief description:
BoolQ: Contains yes/no questions based on paragraphs from Wikipedia.
GSM8K: Covers mathematical problems requiring understanding and solving advanced concepts.
HellaSwag: A dataset for predicting story endings with multiple options, requiring understanding of context.
HumanEval: A collection of programming tasks designed to assess the code generation capabilities of AI models.
MMLU_Humanities: Contains multiple-choice questions in the humanities, testing understanding of a wide range of humanities topics.
MMLU_Other: Includes diverse questions from various fields of knowledge, not necessarily classified as humanities, social sciences, or STEM.
MMLU_Social_Sciences: A dataset of multiple-choice questions related to social sciences, examining understanding of social and behavioral topics.
MMLU_STEM: Focuses on questions in the fields of science, technology, engineering, and mathematics, testing knowledge and understanding of these topics.
OpenBookQA: Contains multiple-choice questions based on general knowledge, requiring understanding and interpretation of facts.
PIQA: A dataset focusing on physical understanding, containing questions about everyday tasks and how to perform them.
SocialIQA: A dataset testing understanding of social interactions and causality in a social context.
WinoGrande: A collection of fill-in-the-blank questions focused on understanding subtle language nuances and reasoning abilities.
At this moment, Microsoft has compared the different models in terms of a single metric, „Accuracy”. More metrics have been defined, and since Azure AI Studio is currently in its Preview version, it is likely that values for Coherence, Fluency, Groundedness, Relevance, and GPTSimilarity will also be added soon.
All these parameters allow us to evaluate the individual models and their overall proficiency in various aspects of text interpretation, answering questions, and generating text. We can also arrive at very interesting conclusions.
For example, comparing the models gpt-35-turbo-0301 (older) and gpt-35-turbo-0613 (newer) would suggest that newer = better. However, this is not so obvious when looking at the results relative to the test data sets. Looking at the datasets gsm8k (simple math) and human_eval (programming), it turns out that the new model is indeed better in math but worse in programming. And that’s a surprise.

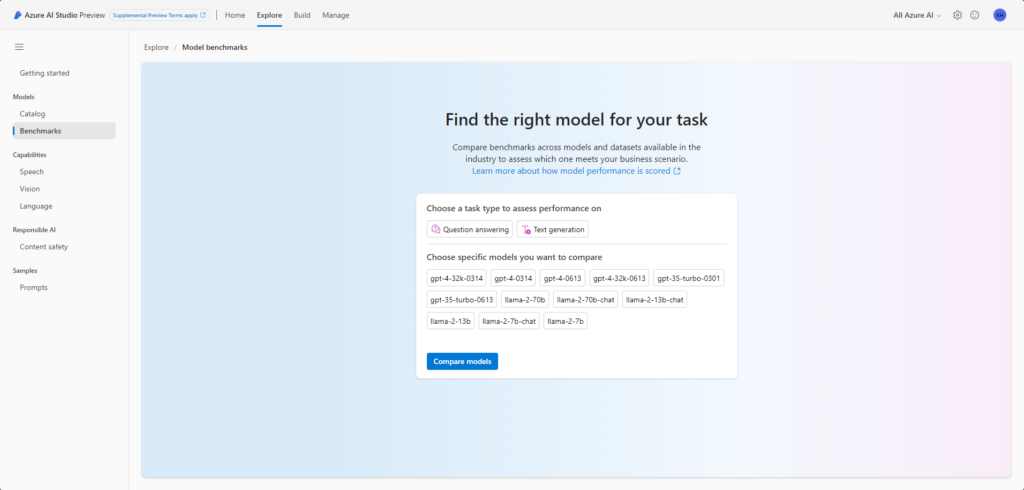
The latest feature at this moment is the ability to compare models in terms of tasks we want to give them, namely text generation and answering questions. Choosing one of these tasks will display a ranking according to quality.

In the next installments of the blog, I will talk more about other functionalities of Azure AI Studio, because as I mentioned at the beginning, it is very comprehensive and combines many possibilities for building, testing, and deploying artificial intelligence solutions.
Links worth mentioning:
https://learn.microsoft.com/en-us/azure/ai-studio/how-to/model-catalog#how-the-scores-are-calculated